What is redis streams and implementing pubsub in python
Pub/Sub
Pub/Sub stands for Publisher/Subscriber, is an architecture pattern that allows services to communicate asynchronously thus provides a way to build decoupled micro-services. Publisher and Subscriber are also known as Producer and Consumer. The Producers and Consumers doesn’t need to know about each other.
PubSub Terminologies
- Publisher - Publishes messages into a channel/topic
- Topic - is where messages are stored and subscribers can subscribe and receive data from the topic.
- Consumers - Receives messages from the subscribed topic and process the message and also fanout the message into other topics.
- Consumer Groups - A group of consumers collaboratively read a topic thus provides scale out for the consumers.
Already feel like “Show me the code”? Its here on github
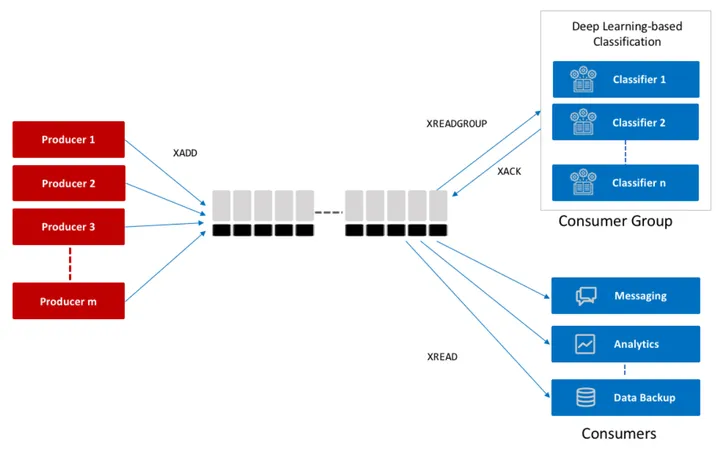
Redis Streams
- Stream stores a series of events sent by the producer.
- Stream acts as the topic in pubsub model.
- Redis stream is a persistent append only data structure.
- Its Naturally ordered.
- ID is autogenerated Unix timestamp + sequence number.
- ID can also be manually set, but it has to greater than the previous ids in the stream.
- Maintains state of the messages that are read by the consumers. Consumers in a consumer group needs to send Acknowledgement after they process the event successfully.
- When consumer groups read messages from the stream in parallel, There is no guarantee that the messages are processed in the same order as in the stream.
- If processing a particular message results in error or it crashed, those messages are kept in pending state like a dead letter queue.
- Other consumers which are running can claim(XCLAIM) the pending messages and retry.
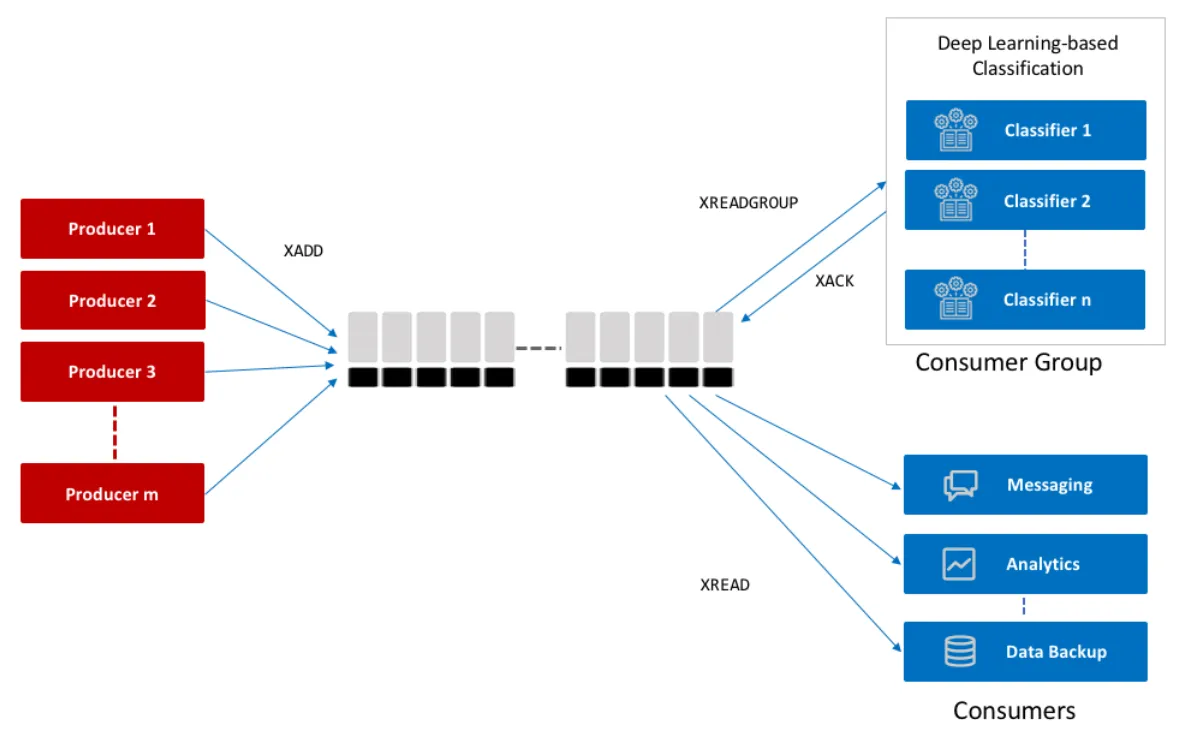
Reading from the stream
There are several ways to consume data from the stream
- XREAD
- XREADGROUP
- XRANGE
- XREVRANGE
Blocking read from the stream
Blocks fo X Milli seconds until a new entry is added to the stream or if no new entry is found and blocking time is reached it returns empty list.
Trimming Strategy
Trimming removes oldest entries from the stream. This is useful delete old messages in a stream with huge volume of messages stored in a stream.
Example:
XTRIM app:events MAXLEN 10000XTRIM - trims a stream to the specified length, thus only latest 10000 messages are kept, rest of the messages are deleted. This can be set as a scheduled job to trim the stream regularly.
XADD app:events MAXLEN 10000 * user_id 1001 action loginMAXLEN can be set when adding a message using XADD. This will trim the stream when it reaches the length.
Why it is better than redis pubsub
- Better visibility on consumer reading messages and failed messages.
- Messages are persisted, so the history of messages are saved in the stream.
- Easier to scale out and consume messages faster.
Redis streams in python
Clone this github repository -> https://github.com/sureshdsk/redis-stream-python-example
We will be using walrus redis library which a useful wrapper around redis-py.
pip install -r requirements.txtThe producer
Generate random sensor data and publish it to the stream called “app:event”. Publishing message returns the message id that is autogenerated by redis. you can also create your own id and publish it.
import sys
import random
from walrus import Database
def main(stream_key, sensor_id):
rdb = Database()
stream = rdb.Stream(stream_key)
msg_id = stream.add(
{
"sensor_id": sensor_id,
"temp": random.random(),
"humidity": random.random(),
},
id="*"
)
print(f"message {msg_id} sent")
if __name__ == "__main__":
stream_key = "app:event"
sensor = sys.argv[1]
main(stream_key, sensor)
Run the producer with different sensor names,
python producer.py sensor1
python producer.py sensor2
python producer.py sensor3Consuming messages with consumer group
Below is the sample flow of the code, to get the full working code head over to the github repo -> https://github.com/sureshdsk/redis-stream-python-example
rdb = Database()
# Takes a group id, consumer id and streams
cg = rdb.consumer_group(group_id, [STREAM_KEY], consumer=consumer_id)
# Create the consumer group.
cg.create()
# Default starts from the latest
# we can set a message ID manually.
cg.set_id(START_FROM_ID)
# Blocking read from a consumer group
streams = cg.read(1, block=BLOCK_TIME)
for stream_id, messages in streams:
for message_id, message in messages:
process_message(message_id, message)
# send Acknowledgement to let redis know this message has been processed
# if not sent redis will mark this as pending
cg.app_event.ack(message_id)Would love to hear your feedback, comments and suggestions.
If you like this article, subscribe to the newsletter and Connect with me on twitter to get updates on my future articles.
Subscribe to my newsletter
Get new posts delivered straight to your inbox.