Posgres materialized views
In this article, we will learn about what is materialized views in postgres and when to use it, what you need to know before you use it and how to implement materialized view with an example.
What is a view?
Postgres view is a virtual table defined by an query that can represent data from one or more tables. the query is executed when the view is referred. It is often used to simplify a complex query.
A view can be very useful in some cases such as:
- A view helps simplify the complexity of a query because you can query a view, which is based on a complex query, using a simple SELECT statement.
- You can grant access permission to users through a view that contains only specific data that the users are authorized to see.
- A view provides a consistent layer even the columns of underlying table changes.
What is a materialized view?
PostgreSQL materialized views allows you to store the result of an expensive query physically in a table and update the data periodically.
The materialized views are useful in many cases that require fast data access therefore they are often used in data warehouses and business intelligence applications.
Maintenance is required because results are static, we need to update view after base table data is modified.
View vs materialized view
| Views | Materialized view |
|---|---|
| Do not store data | Store data |
| Dynamic | Static unless refreshed |
| Used to provide an abstraction for a complex query | Used to cache results of an expensive queries |
How to implement materialized view?
To create a materialized view, you can use the CREATE MATERIALIZED VIEW statement as follows:
CREATE MATERIALIZED VIEW {{view_name}}
AS
{{query}}
WITH [NO] DATA;WITH NO DATA / WITH DATA
This clause specifies whether or not the data inside materialized view should be populated at creation time.
WITH DATA
if you want to load data into the materialized view at the creation time, use the WITH DATA option.
WITH NO DATA
when no data is specified, the materialized view will be flagged as unreadable and cannot be queried until REFRESH MATERIALIZED VIEW is used.
Update / Refresh materialized view data?
Refresh command recomputes the contents from scratch every time you execute refresh.
To load data into a materialized view, use REFRESH MATERIALIZED VIEW statement as below:
REFRESH MATERIALIZED VIEW {{view_name}};**This method uses an exclusive lock and the materialized view is not readable until data refresh is completed. Why because it creates a new table and populates the data and deletes the old table and renames the temp table and commits the transaction. **
Refresh concurrently
When you refresh data for a materialized view, PostgreSQL locks the entire table therefore you cannot query data against it. To avoid this, you can use the CONCURRENTLY option. This uses a weaker lock.
REFRESH MATERIALIZED VIEW CONCURRENTLY view_name;With CONCURRENTLY option, PostgreSQL creates a temporary updated version of the materialized view, compares two versions, and performs INSERT and UPDATE only the differences.
You can query against a materialized view while it is being updated. One requirement for using CONCURRENTLY option is that the materialized view must have a UNIQUE index.
Example
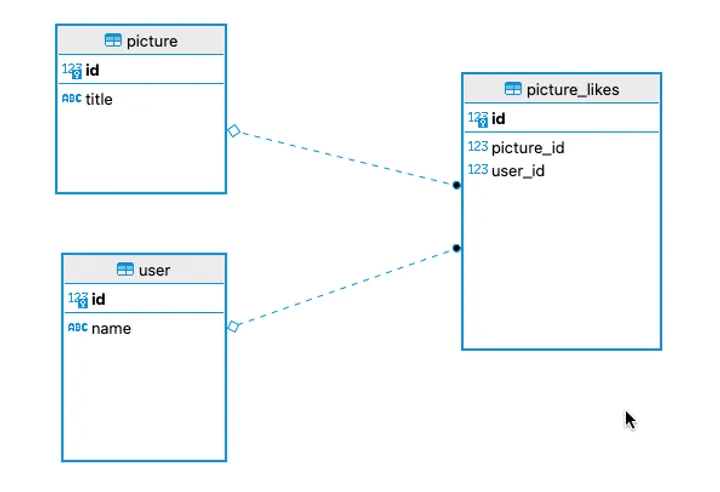
Let us take an simple example of an dummy picture app instagram. Do not focus on the data model as of now, it is just created to showcase an expensive long running query.
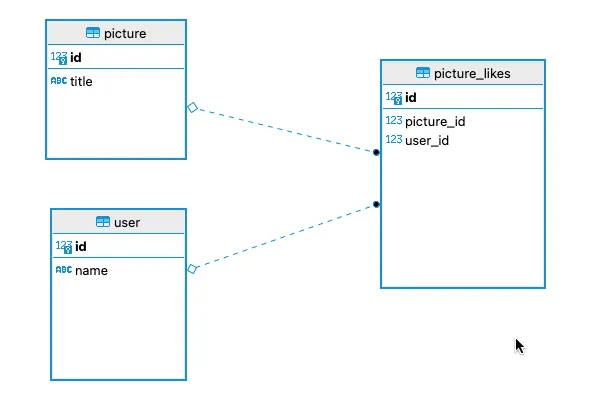
Create sample tables in public schema
CREATE TABLE public.picture (
id bigserial NOT NULL,
title varchar NOT NULL,
CONSTRAINT picture_pkey PRIMARY KEY (id)
);
CREATE TABLE public."user" (
id bigserial NOT NULL,
"name" varchar NOT NULL,
CONSTRAINT user_pkey PRIMARY KEY (id)
);
CREATE TABLE public.picture_likes (
id bigserial NOT NULL,
picture_id int8 NOT NULL,
user_id int8 NOT NULL,
CONSTRAINT picture_likes_pkey PRIMARY KEY (id),
CONSTRAINT fk_pic_id FOREIGN KEY (picture_id) REFERENCES picture(id) ON DELETE CASCADE,
CONSTRAINT fk_user_id FOREIGN KEY (user_id) REFERENCES "user"(id) ON DELETE CASCADE
);Generate random data
-- inserts 1 Million user records
INSERT INTO public."user"
("name")
SELECT 'User '|| s FROM generate_series( 1,1000000) s;-- see total record count
select count(*) from public."user"
-- see first 10 records
select * from public."user" limit 10-- inserts 1 Million picture records
INSERT INTO public.picture
(title)
SELECT 'Picture_'|| s || '.png' FROM generate_series( 1,1000000) s;-- see total record count
select count(*) from public.picture
-- see first 10 records
select * from public.picture limit 10-- inserts 3 Million picture likes
do $$
begin
for r in 1..3 loop
WITH users AS (
SELECT *
FROM generate_series(1, 1000000)
)
INSERT INTO public.picture_likes
(picture_id, user_id)
SELECT r, generate_series FROM users;
end loop;
end;
$$;-- see first 10 records
select * from public.picture_likes limit 10
-- see total records
select count(*) from public.picture_likes-- join with picture table and get aggregates
select pl.picture_id, p.title , count(*) from picture_likes pl
inner join picture p on p.id = pl.picture_id
group by pl.picture_id, p.title-- explain
explain analyse select pl.picture_id, p.title , count(*) from picture_likes pl
inner join picture p on p.id = pl.picture_id
group by pl.picture_id, p.title
Finalize GroupAggregate (cost=254480.64..616792.67 rows=3000000 width=34)
Group Key: pl.picture_id, p.title
-> Gather Merge (cost=254480.64..568042.67 rows=2500000 width=34)
Workers Planned: 2
-> Partial GroupAggregate (cost=253480.62..278480.62 rows=1250000 width=34)
Group Key: pl.picture_id, p.title
-> Sort (cost=253480.62..256605.62 rows=1250000 width=26)
Sort Key: pl.picture_id, p.title
-> Parallel Hash Join (cost=19576.00..67081.27 rows=1250000 width=26)
Hash Cond: (pl.picture_id = p.id)
-> Parallel Seq Scan on picture_likes pl (cost=0.00..31609.00 rows=1250000 width=8)
-> Parallel Hash (cost=11518.67..11518.67 rows=416667 width=26)
-> Parallel Seq Scan on picture p (cost=0.00..11518.67 rows=416667 width=26)
JIT:
Functions: 17
Options: Inlining true, Optimization true, Expressions true, Deforming trueIt takes about 7 seconds to execute in my machine. Yes, we can optimise to some level with indexes. But for the sake of this tutorial, we are gonna proceed without it.
Create materialized view and update materialized view
CREATE MATERIALIZED VIEW likes_report_mv
AS
select pl.picture_id, p.title , count(*) from picture_likes pl
inner join picture p on p.id = pl.picture_id
group by pl.picture_id, p.title
WITH DATA;Select results from materialized view
select * from likes_report_mv;Add some record into the base table
INSERT INTO public.picture_likes
(picture_id, user_id)
values(4,1);Results in materialized view is not updated since it is static
select * from likes_report_mv;Refresh results in materialized view
REFRESH MATERIALIZED VIEW likes_report_mv;Select results from materialized view
select * from likes_report_mv;Refresh concurrently
Create unique index on materialized view
CREATE UNIQUE INDEX pic_id_uidx ON likes_report_mv (picture_id);Select results from materialized view
select * from likes_report_mv;Add some record into the base table
INSERT INTO public.picture_likes
(picture_id, user_id)
values(4,2);Select results from materialized view
select * from likes_report_mv;Refresh results concurrently
REFRESH MATERIALIZED VIEW CONCURRENTLY likes_report_mv;Select results from materialized view
select * from likes_report_mv;Have any questions or suggestions? Please comment below. Learnt something new? Share this article with others who may find this useful. Stay tuned for upcoming articles. Subscribe to the newsletter and Connect with me on twitter to get my future articles.
Subscribe to my newsletter
Get new posts delivered straight to your inbox.